
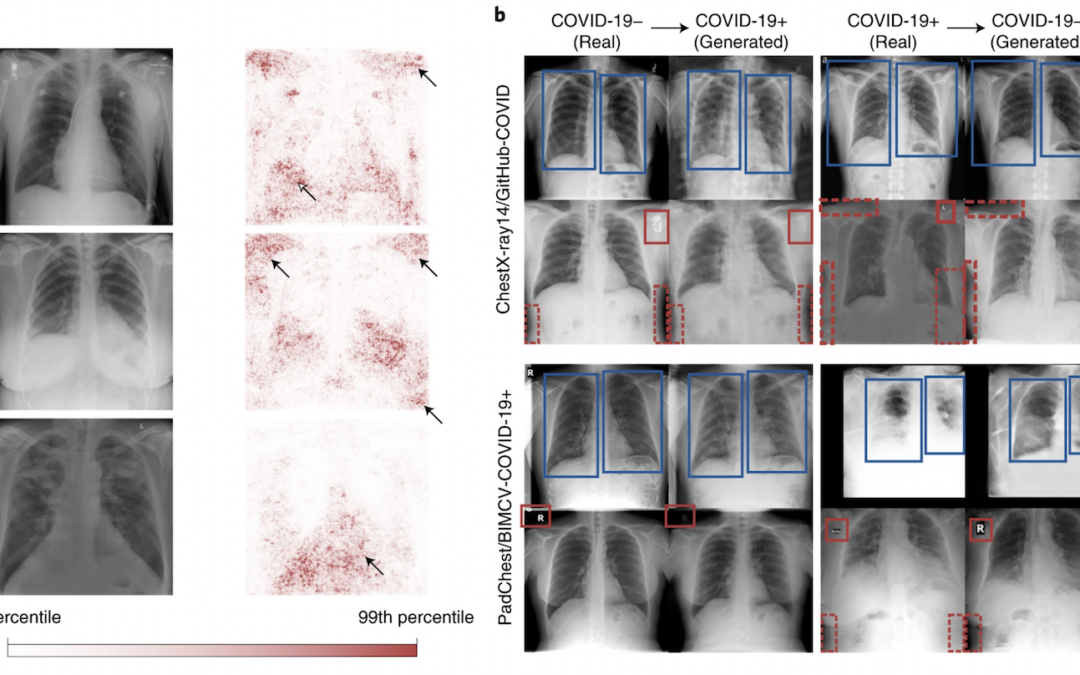
This article published in Nature Machine Intelligence explains how deep-learning classification algorithms can learn non-medical and irrelevant information by making “shortcuts”, and then replicate them in an external validation base.
This article highlights the importance of the quality of the data selected for AI learning to reduce “shortcuts”. Even so, the possibility of irrelevant learning is not entirely absent, so it seems necessary to focus on explainable AI approaches to overcome this bias.