
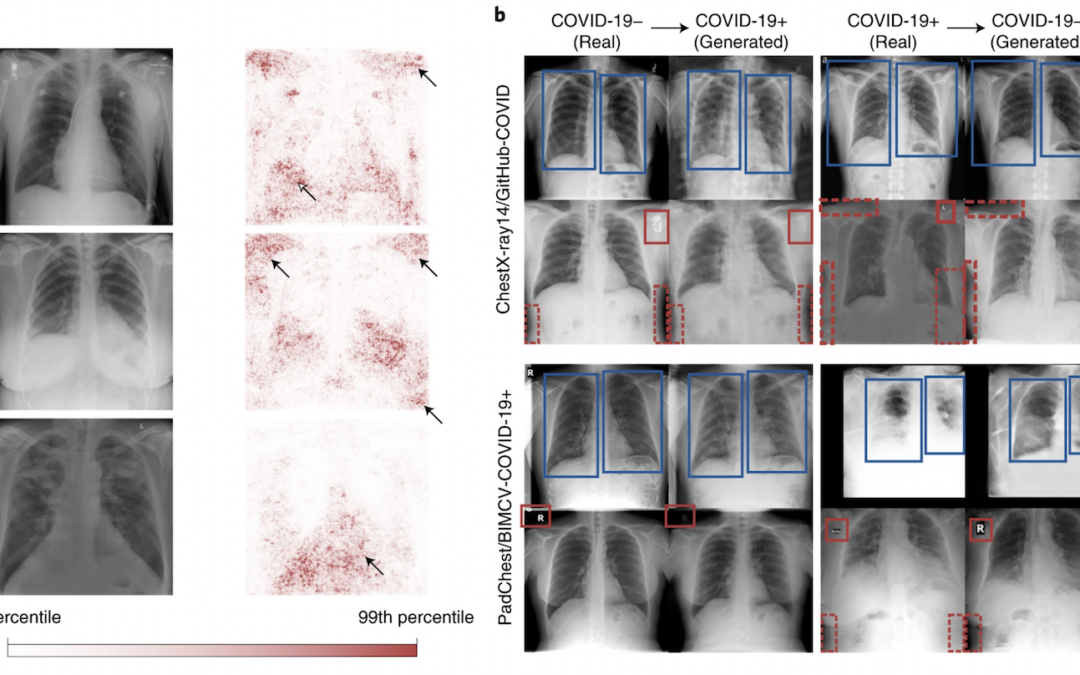
Cet article publié dans Nature Machine Intelligence explique comment les algorithmes de classification en apprentissage profond (deeplearning) peuvent apprendre des informations non médicales et non pertinentes en faisant des « raccourcis », puis les répliquer dans une base de validation externe.
Cet article met en évidence l’importance de la qualité des données retenues pour l’apprentissage de l’IA afin de réduire les « raccourcis ». La possibilité d’un apprentissage non pertinent n’étant tout de même pas totalement absent, il semble nécessaire de se concentrer sur des approches d’IA explicable pour pallier ce biais.